 ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
ViP-LLaVA directly overlays the visual prompt with the original image, then feeds the image to the multimodal model. Our approach shows several benefits:
- Simply Design:. No specific region encoding module is needed.
- Generalize to Arbitrary Visual Prompts:. Users can draw arbitrary visual prompts such as scribble, circle and point.

During Trianing, we use 8 diverse visual prompts, including mask contour, ellipse, bounding box, triangle, scribble, point, arrow, and mask. Note that the prompts not only have diverse shapes, but they also have diverse colors, transparency values, widths, scales, and directions.

 Performance
Performance
 Traditional Region-level Benchmarks: ViP-LLaVa achieves state-of-the-art performance.
Traditional Region-level Benchmarks: ViP-LLaVa achieves state-of-the-art performance.
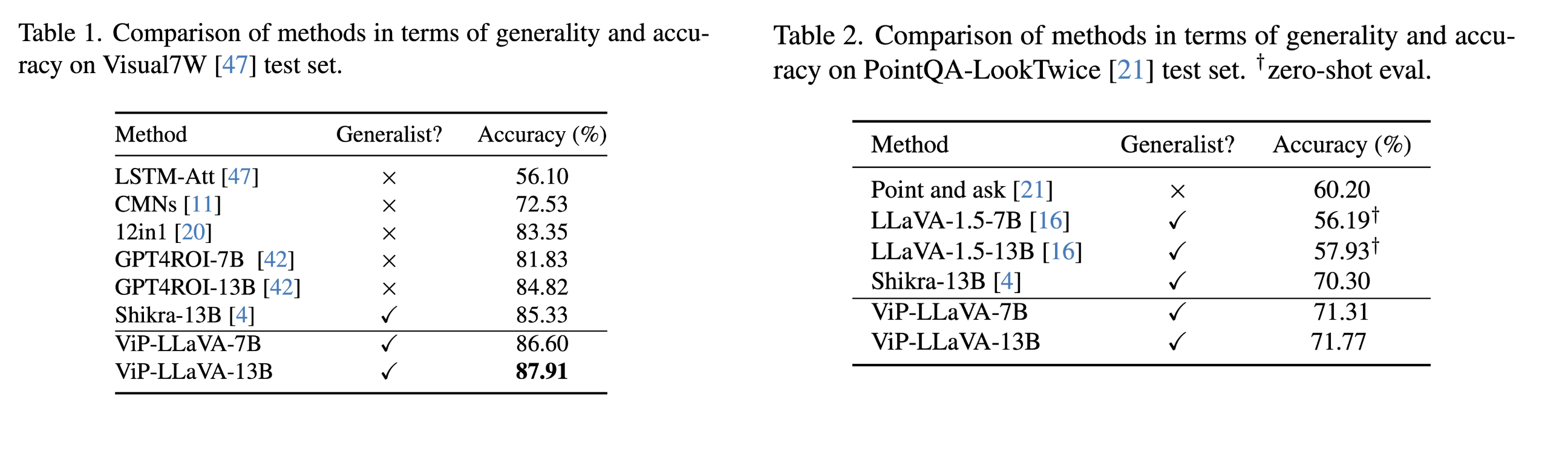
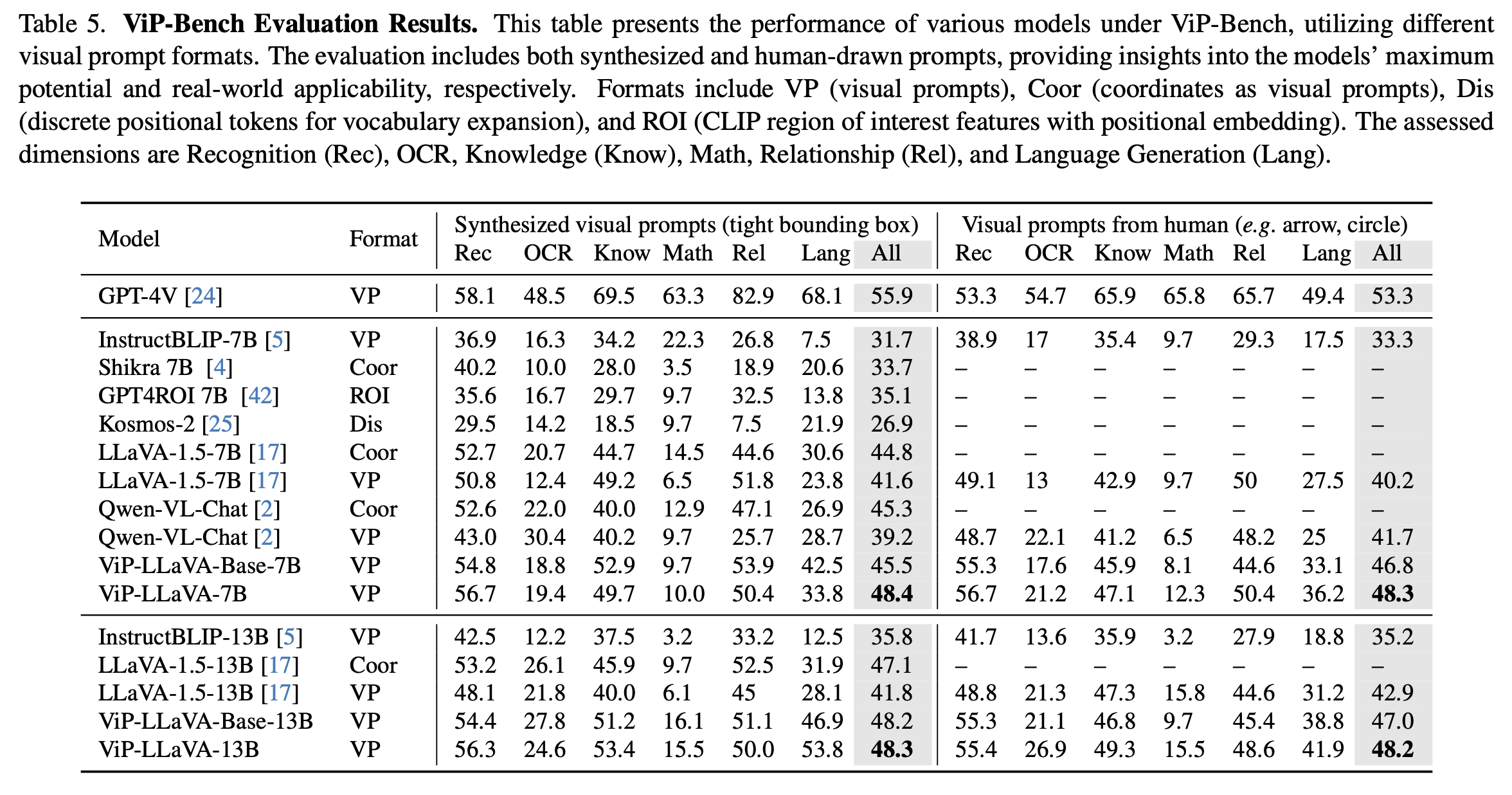
 ViP-Bench: SoTa among Open-sourced Models
ViP-Bench: SoTa among Open-sourced Models
ViP-Bench is the first zero-shot region-level benchmarks that comprehensively evaluate the capability of multimodal models in understanding visual prompts. ViP-Bench is composed of 303 samples, evaluating 6 capbilities including recognition, OCR, knowledge, math, object relationship reason- ing, and language generation. ViP-Bench have two formats: (1) Bounding box format, and (2) arbitrary visual prompts annotated by human.

GPT-4V is still the strongest multimodal model in zero-shot visual prompting understanding. ViP-LLaVA shows impressive performance on ViP-Bench. Most region-specific multomodal models such as Kosmos-2 even show lower performance than the image-level multimodal models.
Examples on Visual Prompt Understanding
Here we should some cases where GPT-4V fails to recognize the visual prompts while ViP-LLaVA succeeds. However, in most cases, GPT-4V shows robust and strong performance in visual prompt understanding.

BibTeX
@inproceedings{cai2023vipllava,
author = {Cai, Mu and Liu, Haotian and Mustikovela, Siva Karthik and Meyer, Gregory P. and Chai, Yuning and Park, Dennis and Lee, Yong Jae},
title = {Making Large Multimodal Models Understand Arbitrary Visual Prompts},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = {2024}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Related Links: [LLaVA] [Insutrction Tuning with GPT-4]